This means it's time for a little practice for me, and a mini-tutorial for you (and future me).
What we're going to do
We're going to build a small server application based on Freya which will serve JSON and be a nice RESTful (in the loose sense) API.
Then, we're going to configure Fable with Elmish to load data from that API. The crucial thing here is that we're going to configure both projects such that we have a seamless development work flow; automated recompile and restart of the server on code changes, and automatic recompile/reload of the Fable UI on change.
The server
Make sure your dotnet core Freya template is up to date:
1
| |
In a root directory for our overall solution, run:
1
| |
This will create a new directory called "FateServer" with a F# project in it. Go into the directory and make sure everything has restored correctly:
1 2 3 | |
One thing I've been slowly learning with dotnet core is that the restore run by default during a build doesn't always seem to be as effective as actually running the full restore command. Just in general, if Core is behaving strangely, running restore is a good starting point.
Next up is making our server log something: by default, Kestrel logs basically nothing.
Install the logging package (it's not part of the default Freya template):
1 2 | |
In Program.fs add the following at the end of the open statements:
1 2 3 4 5 6 | |
Then inject the method into your WebHost configuration pipeline:
1 2 3 4 5 | |
Hey presto! Run your application and get logs!
To finish off the niceties of civilized development, let's add the watch command to our server.
Crack open the fsproj file and add the following ItemGroup to it:
1 2 3 | |
Run dotnet restore and from now on running dotnet watch run to start continuous development with file watching should work.
Now we just need to serve up some JSON. We want a send a format which Fable understands, and the kind people at the Fable project have written a Newtonsoft configuration for doing exactly that.
Stop watching the build long enough to run:
1 2 | |
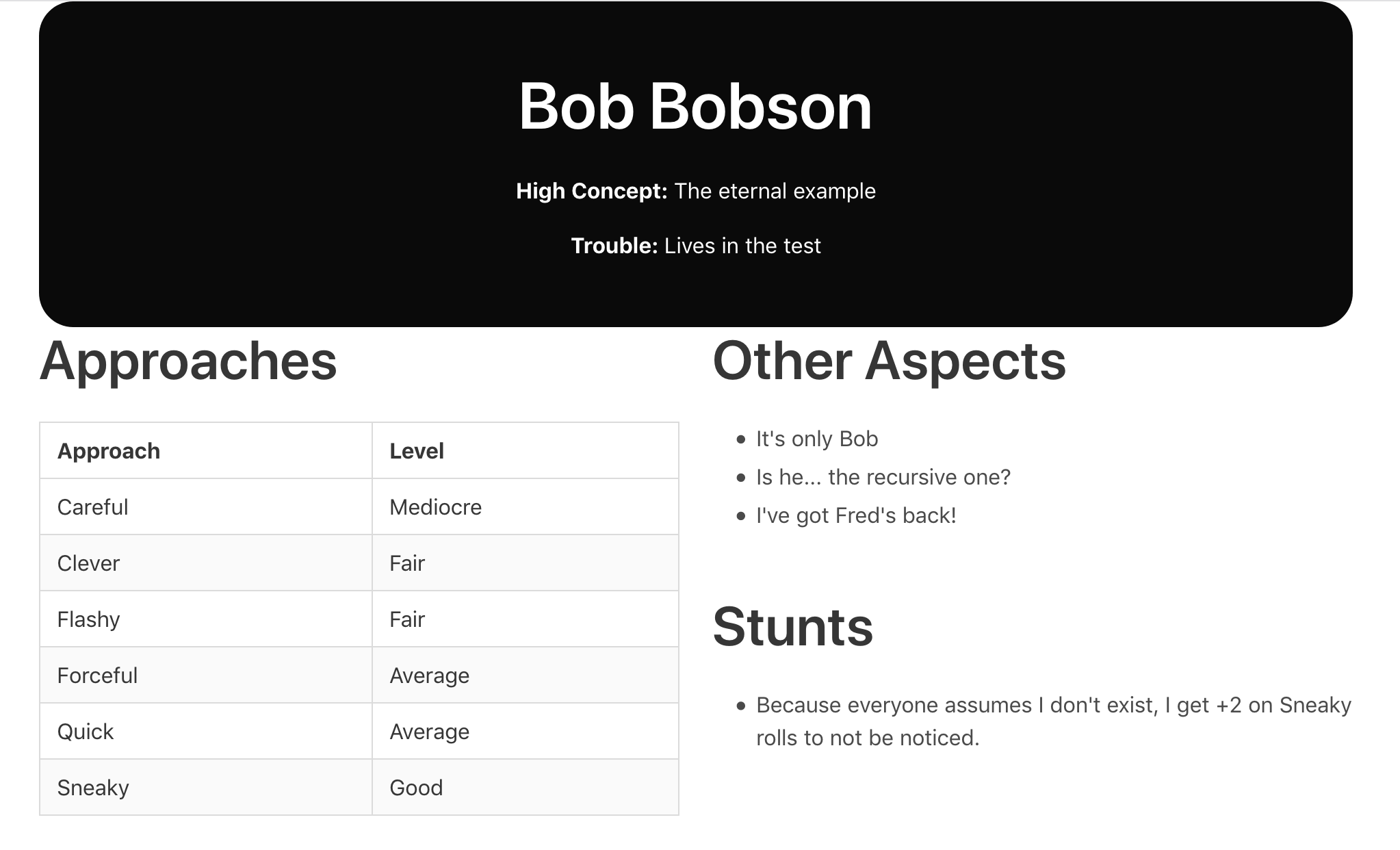
Next, set up the domain. Create a new file Character.fs (we're going to be sending back and forth Fate Accelerated characters as data). Make sure you add it to the project file before Api.fs.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
Now move across to Api.fs. You'll see that it defaults to a single "greeting" endpoint which responds with a text response. Let's add a helper for sending JSON correctly, immediately after the existing open statements:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Next, delete the entire rest of the file and add the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | |
There's quite a lot going on in there, but what we've defined with characterMachine is a resource which checks if a character exists, and sends it as Fable readable JSON if it does. We then configure a route to point to it.
Critically, we also turn on CORS (Cross Origin Resource Sharing) for localhost:8080 for debug builds. This will enable requests from our Fable client running it's development server on a different port to talk to the server.
Edit: Zaid Ajaj points out that you can also configure webpack's dev server to proxy to your development front end. If you're writing a system where your API and client will be running on the same domain, check out how to do that below.
The client
Go back up into the root directory of the solution, and run:
1
| |
To get a dotnet core template for Fable with F# wrappers for React and Bulma - as well as Elmish pre-installed.
Then run:
1
| |
To create our client application.
Go into the newly created project directory, and use the built in build scripts to get everything up and running:
1 2 | |
On first run, it will download most of the internet, but such is modern net development.
Browse on over to http://localhost:8080/ to see the base template before we start hacking away!
Very pretty: and in App.fs we can see the nice clean Elmish code driving it.
If you're running both API and client on the same domain, this is also a good time to update your webpack config (you'll find webpack.config.js in your FateClient directory). Amend the devServer section as follows:
1 2 3 4 5 6 7 8 9 10 11 12 | |
If you do this, you'll want to change the URL below used to load the data.
Now! Let's start hacking away. Firstly, we're going to want to share our character types. I've decided here that they are owned by the server, so we need to link the file into the Fable project.
In FateClient.fsproj, add change:
1 2 3 | |
to:
1 2 3 4 | |
Now we can load up our character. In App.fs, it's time to expand our model. Change our Elmish app as below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 | |
And there you have it - a simple app that loads "Bob" from our server, using the generic fetchAs method to cast the JSON back into our strongly typed world. Making the application interactive and more attractive is left to the user; it gets quite addictive with a nice type safe wrapper over React and auto-reloading.
Till next time…