So, a couple of weeks ago I went to the Brighton Functional Programmers meet up. It was a fun night, and at one point I ended up live coding in front of a room of functional programmers trying to give examples of lazy and strict evaluation.
The canonical go to tool for the job, is of course the infinite sequence and being stared at by a bunch of people and having syntax highlighting but no compiler, the first thing my brain pulled out of the air was this:
Which prompted one of the people attending (hi Miles!) to comment "let's see that in Haskell without the bizarre looping generator". Roughly - I'm slightly paraphrasing here given the couple of weeks in between. He has a bit of a point, this isn't the most functional looking sequence generator in the world, and it looks like quite a lot of code to just generate a lot of ones.
As always in these situations, I had of course thought of several other alternatives before I even reached my chair, so I thought I'd have a quick survey of them and their advantages and disadvantages.
My first thought was that I'd missed the obvious and succinct option of just generating a range. In F# (as in Haskell) the 1 .. 10 notation generates a list of the integers from 1 to 10. Unfortunately:
Unlike Haskell, you can't have an unbounded range, nor can you set the "step" to zero to just keep on generating the same number. So you're limited to generating very big, but definitely not infinite sequences:
But hey! We're in functional world. So if we can't use sneaky built in syntax constructs, the next obvious choice is a recursive function:
This is definitely infinite, and definitely functional in style. Bit verbose, of course, but it least it won't stack overflow as F# implements tail call recursion. It's verbose, but it does also have its advantages. It's trivial to pass things round in the recursive function (previous values from the sequence, etc) making this a very flexible way of generating sequences.
And, of course, let's not ignore the standard library. The Seq module gives us a couple of methods designed specifically for generating (potentially) infinite sequences.
Seq.initInfinite just takes a function that returns a sequence value based on the index of that value:
As long as a simple mapping from index to value exists, this is both clear and concise. In theory, of course, it also suffers from the same issue as my range generators above: if your index exceeds the valid size of an Int32 you're out of luck.
Seq.unfold may seem less intuitive, but in my mind is the more flexible and powerful solution. I tend to come across examples where it's easier to generate a sequence based on either some state or the previous term than by index, and that's exactly what unfold allows you to do:
It will also happily generate sequences forever if your generating function allows.
So, how does it actually work? Let's look at a (slightly) more complex example that actually makes use of some state:
What's going on here then? Well, unfold takes two arguments. The first is a function that takes a 'State and returns an Option<'T * 'State>. In our simple example above, both 'State and 'T are of type int but there's no requirement for them to be of the same type. If at any point the function returns None, the sequence ends. In our example, we always return Some, so our sequence is infinite (at least until it runs out of integers) and we're return a tuple of two values - the first of which will be used as the next term in the sequence, and the second which will become the new state.
The second argument to unfold is the starting state. In our case, this means the number that will be the first term in the sequence, and then we'll add one to it each time.
Let's round this out with an example that uses different types for the state and the terms of the sequence, which will hopefully now make some sense:
I'm sure that you've always needed a convenient way of cycling through every minute of the day repeatedly, with a nice readable string representation.
So, as a follow up to this post I'm in the final stages of preparing a presentation for this Friday introducing an audience of (mostly) fairly experienced developers to F# and F# syntax. The main reason for this is to get a number of people up to speed enough on reading F# that they can have a better experience at the Progressive F# Tutorials at the end of the month. So the aim here isn't to get people fully autonomous and writing code right now, but to allow them to read the bulk of the example code in the tutorials and follow what's going on.
The general approach I've gone for is to set up a Git repository that has a series of tagged snap shots I can check out as I work through the concepts I'm planning to cover. This will enable me to actually demonstrate and run pieces of code, answer questions and make live modifications and then always jump back to a known starting point for the next section of the talk. Given the people involved have all done some .net development and I don't need to cover things like Visual Studio usage and projects, all of the code is contained in a single Program.fs file in a console app. I've included the snapshot of the file from each tagged commit below, with a brief overview of what I'm planning to introduce before skipping to the next snapshot.
With a full screen Visual Studio editing session, I should be able to make the code large enough to be visible and reasonably rapidly guide people to the areas where the code has changed.
A combination of the excellent PaperCut project and a local 'http request to email' service pretending to be an SMS sender, we should be able to see messages being generated by the code as we go along.
After the session, I'm planning to mention Chris Marinos' koans and Try F# (especially given that Rachel Reese is running a session at the tutorials for those who are going).
Please note that these are up here for comment and suggestions at this point - I'll be pushing up the actual Git repository and a screencast (I hope) after the event. The code is designed to be a prop for the talk rather than an independent resource - for that I'd always point people to the koans/Try F# first.
But you are a chosen people, a royal priesthood, a holy nation, God’s special possession, that you may declare the praises of him who called you out of darkness into his wonderful light. (1 Peter 2:9)
Warning: this post may contain theology and other non-programming related
material. You have been warned…
Our church started a new sermon series last week, and as the
sermon was going on various other bits and pieces came together in my mind, and
I knew that I was going to have to at least try and get them down in writing or
they were going to run around my head for the next few days.
It comes up regularly for us as Christians that God isn't small enough to be
contained to Sunday mornings - he wants a larger part of our lives than that,
in fact the central part. But the idea of worshipping God with your whole
life often begins to get a bit weird when you actually stop and think about it.
Worship ('to assign worth to something') is not a strange idea to any of us,
although we might not use that language - I'm sure you can all think of a
respected author, favourite footballer or awe inspiring musician. And if you
buy into the whole Christian idea of who and what God is (infinitely powerful
and awesomely loving, perfect judge who offers grace, amazing sense of humour)
then the idea that a Christian is going to worship God also shouldn't seem that
strange.
But with your whole life? There's no doubtbiblically
or in the teachings of both Christian teachers
and Jewish tradition that this is
precisely what is expected of us. But… when you write computer code as a day
job, what does that actually mean?
And then it struck me. It means being a Michael Meeks or a Jon Skeet. Probably not in the
specific details - I've not met either of them personally, but in the attitude
they show to life and the people around them. If you're not in the programming
field (probably, if you don't happen to be in a similar area of the programming
field to me…) you're not likely to have heard of them. But they've both
developed an enormous amount of respect in a field that is frequently full of
highly opinionated staunch atheists while being openly professing Christians.
So we wrap round to where we started - the idea from 1 Peter of
all Christians being priests. (I'm not using the term here in the catholic
sense, so bear with me…). This comes up a lot when people relate one of the
core Christian doctrines - that people who have come into a relation with
Christ can come directly to God without an intermediary. But that wasn't the only
role of priests in the Old Testament. Yes, they were the only people who could
enter God's presence… but they weren't only going there for themselves. They
were the intermediaries, 'introducing' others to God's presence, carrying
blessings from God to them and petitions from them to God.
Jon and Michael are dedicated to
what they do, they are good at it and they are 'graceful'. In the sense that
they treat the people around them with respect and as professionals, teaching
and helping without regard to the others faith and without forcing argument and
discussion where it's not wanted. Both are obviously willing to talk to people
who want to (Michael even links to a fun page on Christian Think Tank for those who are
interested), but there isn't a pressure there.
And maybe that's what some small part of everyday worship looks like; I can't help feeling that by
being respectable (in the sense of, worthy of some respect) and making the fact
of their faith public, people like Jon and Michael have been doing their bit to
draw others closer to this God I worship. They've caused a doubt and a second
look at what faith really means in the mind of those who would otherwise live
in an atheist bubble, carelessly dismissing the idea of God as the ramblings of
the obviously stupid and insane. Because these men are clearly neither.
This is encouraging to me, and I hope to a lot of out there who go to work, work hard
and tell people that you made it to church this Sunday. Because if you look
around you'll probably begin to see these people around you, the Jons and Michaels
who are making a difference just by living a life based on Christ's in the everyday.
And guess what? If you're a Christian, letting people know without pressure and
getting your coding/plumbing/teaching/building/etc. done you're probably making a difference
too. You might be the last to see
it, but I'm sure others do.
As part of writing up notes for introducing F# as a programming language to experienced C# devs I was looking for examples
of heavily OO code being implemented in F#. Then I realised that I'd written at least one suitable example myself.
In the NuGetPlus project I needed to implement a ProjectSystem class that was almost a direct copy of the MSBuildProjectSystem in the NuGet commandline client.
So without further ado, F# and then C# versions of a class with inheritance and which implements several interfaces.
So, in a fit of enthusiasm my boss bought 15 tickets to the London Progressive F# Tutorials when he saw the early birds pricing (did I mention it's nice working here?). Several of the people who have been assigned tickets have asked to go largely because they are new to F#, so I've been asked to put together a starter session to teach them the basics. I've tried this once before and it was a fairly successful session (F# was adopted as a official supported language in the company partly due to feedback following it). But it was still pretty rough around the edges, and as normal with these things, you always want to do them better the next time round…
So, with a target audience of curious, experienced C# devs I'm wondering about the best approach. The initial session needs to fit in an hour, although I can do individual follow ups afterwards.
My current thinking is to take a block of C# code (smtp sender?) that is fairly straight forward but 'production ready' in the sense that it includes error handling, logging, etc. Then do a straight re-write in F# live coding. And then start refactoring to more idiomatic F# as we go along.
Features I feel would be important to cover:
Basic syntax (let, functions, if … then, etc)
Common idioms (|>, Seq.map)
At least one computational expression (probably an error handling one; simpler than async in some ways)
Several examples of using the match statements
…which probably means at least one DU, possibly for error handling
Records and { … with … } expressions
I've got a week or two to prepare, so what I'm really hoping for at this point is suggestions and ideas from people for how to improve this as a session idea, things that threw you when you first started writing F# you think should be covered, whether you think this is a stupid idea for a session from the concept up, etc. Once the session is completed I'll be posting the slides and hopefully a screen cast of it as I did last time for use by fsharp.org.
Suggestions on the piece of C# code to translate would also be appreciated - either in terms of ideas of the type of code, or actual open source code that would serve as a code starting point.
FsCheck is a property based testing library for .net. Based on QuickCheck and scalacheck it can be easily called from any .net language.
But what is property based testing? It's a technique that allows us to define 'properties' for our code, and then let the library try and find input values that break these properties. Let's take an example and see what happens.
The Brief
I've been tasked with writing the backend of a public facing endpoint. Customers can pass user defined input into the endpoint, and we'll add it to their 'booking'. Once they have called the service once with any particular input, we should ignore any further calls with the same value.
Previous architectural decisions mean that we are storing the bookings as XML documents.
(Why yes, I do know this is slightly contrived. Thank you for asking. Hopefully though, you should begin to see similarities to real scenarios you've coded against.)
What can we get out of this?
Well, as well as any normal exploratory unit tests we may decide to write (which I'll ignore for this article to keep things succinct) we can determine a few properties that should always hold true in the brief above:
Repeatedly calling the code with the same input xml document and the same input text should always give us the same result. I.E., the code should be idempotent.
Our code should never remove nodes from the XML. The result document will always be the same or longer than the original.
The input is supplied by the customer. It's about as trustworthy as a hungry stoat on speed.
Let's get started
Let's start off with the core 'business logic' function of this code. We'll ignore for this post how the input gets to the function, and how the document is persisted. It's signature (F# style) will be:
val AddEnhancement :
xDoc:System.Xml.Linq.XDocument -> input:string -> System.Xml.Linq.XDocument
After referencing System.Xml and System.Xml.Linq, our first, very naive, attempt at the implementation looks like this:
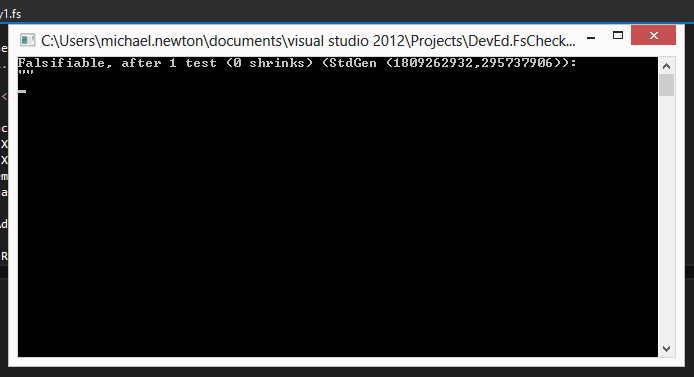
We know this isn't right - it's blatantly not idempotent. So let's try and get our failing test.
Although FsCheck does expose a set of NUnit plugin attributes, for this blog post I'm just going to run the tests via a console app. So; add a new F# console app to your solution, add references to System.Xml, System.Xml.Linq and your library project then grab FsCheck (it's on NuGet) and we'll see what we can do.
First, we'll need to add a property that we want to test. A property is simply a function that takes a data type FsCheck knows how to generate, and returns a bool. FsCheck knows how to generate strings, so our idempotence property looks something like this:
Failing test. Interestingly (and if you check the documents, not coincidently), FsCheck has found the 'simplest' possible failure case: "". Of course, it was helped on this occasion by the fact it was also the first input it tried.
So; let's add some checking to AddEnhancement to make sure we don't re-add the same input more than once.
And this is where the full power of FsCheck starts becoming apparent. I know my input is untrusted, so I've told it to generate any string. And it believed me, and has created an input string that breaks System.Xml.XmlEncodedRawTextWriter.WriteElementTextBlock. This is not a unit test I would have thought to write myself, as I'd managed to miss that the fact that not all utf-8 characters are valid in utf-8 encoded xml. In fact, it took me more than a few minutes to work out why it was throwing.
At this point FsCheck has revealed to us that our initial brief is actually incomplete; we've told the customer that we're willing to accept utf-8 strings as input, but our storage mechanism doesn't support all utf-8 strings. To even get FsCheck to run, we'll have to decide on an error handling strategy - and importantly, it will have to be a strategy that still fulfils the initial properties specified (unless we decide that what we've discovered so fundamentally breaks our initial assumptions that they need to be re-visited).
This is a toy project so I'm going to bail slightly on this one: I'm going to assume that invalid values just add an error node with a 'cleaned' version of the input which could then be reviewed by a human at a later date. This has the advantage that it still fulfils all of our properties above.
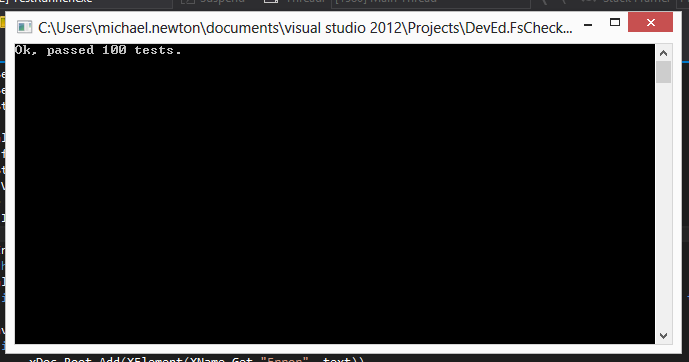
Fortunately for us, in .NET 4.0 and above there is a function in the System.Xml namespace called XmlConvert.IsXmlChar which does roughly what you would expect from the name. Let's add an invalid character filter, and an active pattern to tell us if any characters have been removed:
As a bonus extra, I've included below a somewhat expanded version of the test code. Remember I said that FsCheck already knows how to generate strings? Unfortunately it doesn't know how to generate XML out of the box, but I was pleasantly surprised how quick and easy it was to write a naive XML generator. It generates XML like this. Also, check out the CheckAll function used at the end which allows you to build and run 'property classes' to group families of properties together.
And, of course, per the specification, it checks that the 3rd property above holds true (that adding enhancements never reduces the size of the document).
moduleFsCheck.Examples.TestsopenFsCheckopenDevEd.FsCheckopenSystem.Xml.LinqletbaseDocText="""<?xml version="1.0" encoding="UTF-8"?><root />"""typeXmlTree=|NodeNameofstring|Containerofstring*List<XmlTree>letnodeNames=["myNode";"myOtherNode";"someDifferentNode"]lettree=letrectree's=matchswith|0->Gen.mapNodeName(Gen.elementsnodeNames)|nwhenn>0->letsubtrees=Gen.sized<|funs->Gen.resize(s|>float|>sqrt|>int)(Gen.listOf(tree'(n/2)))Gen.oneof[Gen.mapNodeName(Gen.elementsnodeNames);Gen.map2(funnamecontents->Container(name,contents))(Gen.elementsnodeNames)subtrees]|_->invalidArg"s""Size most be positive."Gen.sizedtree'lettreeToXDocxmlTree=letrecinnercurrentNodechildren=letchildMatchchild=matchchildwith|NodeNamename->XElement(XName.Getname)|Container(name,contents)->letelement=XElement(XName.Getname)innerelementcontentscurrentNode.Add(List.mapchildMatchchildren|>List.toArray)currentNodematchxmlTreewith|NodeNamename->XDocument(XElement(XName.Getname))|Container(name,contents)->letdoc=XDocument(XElement(XName.Getname))innerdoc.Rootcontents|>ignoredoctypeXmlGenerator()=staticmemberXmlTree()={newArbitrary<XmlTree>()withmemberx.Generator=treememberx.Shrinkert=matchtwith|NodeName_->Seq.empty|Container(name,contents)->matchcontentswith|[]->seq{yieldNodeNamename}|c->seq{forninc->n}}typeXmlUpdaterProperties()=staticmember``AddEnhancementisidempotent``(data:string)=((AddEnhancement<|AddEnhancement(XDocument.ParsebaseDocText)data)data).ToString()=(AddEnhancement(XDocument.ParsebaseDocText)data).ToString()staticmember``AddEnhancementisidempotentondifferentxmlstructures``(xmlDoc:XmlTree,data:string)=(AddEnhancement(treeToXDocxmlDoc)data).ToString()=(AddEnhancement(AddEnhancement(treeToXDocxmlDoc)data)data).ToString()staticmember``AddEnhancementneverreducesthenumberofnodes``(xmlDoc:XmlTree,data:string)=Seq.length((treeToXDocxmlDoc).DescendantNodes())=Seq.length((AddEnhancement(treeToXDocxmlDoc)data).DescendantNodes())Arb.register<XmlGenerator>()|>ignoreCheck.QuickAll<XmlUpdaterProperties>()System.Console.ReadLine()|>ignore
Thanks for reading this far. If you want to play yourself, a full copy of the example code is on GitHub with an MIT license.
So, first post with the new blogging engine. Let's see how it goes.
Our code base at 15below started it's life a fair
while ago, well before any form of .NET package management became
practical. Because of that, we ended up building a lot of code in
'lockstep' with project references in code as there was no sensible way
of taking versioned binary dependencies.
That's fine and all, but it encourages bad code hygiene: rather than
having sharply defined contracts between components, if you've got them
all open in the same solution it becomes far too tempting to just nudge
changes around as it's convenient at the time. Changes can infect other
pieces of code, and the power of automatic refactoring across the entire
solution becomes intoxicating.
The result? It becomes very hard to do incremental builds (or
deployments, for that matter). This in turn makes for a long feed back
cycle between making a change, and being able to see it rolled out to a
testing environment.
So as part of the ongoing refactoring that any long lived code base needs to
keep it maintainable and under control, we've embarked on the process of
splitting our code down into more logically separated repositories that
reference each other via NuGet. This will require us to start being much
more disciplined in our semantic versioning than we
have been in the past, but will also allow us to build and deploy
incrementally and massively reduce our feed back times.
As part of splitting out the first logical division (I'd like to say
domain but we're
not there yet!), I created the new repository and got the included
assemblies up and building on TeamCity. It was only then (stupidly) that
I realised that we had several hundred project references to these
assemblies in our code. There was no way I was going to update them all
by hand, so after a few hours development we now have a script for
idempotently updating a project reference in a [cs|vb|fs]proj file to a
NuGet reference. It does require you to do one update manually first;
especially with assemblies that are strongly signed, I chickened out of
trying to generate the reference nodes that needed to be added
automatically. The script also makes sure that you end up with a
packages.config file with the project that includes the new dependency.
It should be noted that this script has only seen minimal testing, was
coded up for one time use and does not come with a warranty of any kind!
Use at your own risk, and once you understand what it's doing. But for
all that, I hope you find it useful.
Async.Parallel |> Async.RunSynchronously is great for running a load of stuff in parallel in F#, as long as you don't mind them all running at the same time.
Often, though, you want to map across a sequence and run functions on the elements in parallel, but with a limit to how many are being processed concurrently. Whether you're doing something CPU heavy and there's no point running more than the number of processors on the box, or whether you know that you'll swamp a remote server if you just dump all of your connections on it at once, this issue comes up surprisingly often.
As a first stab, you might be tempted to do something like this (if you think like I do):
So, you’ve written your brave new F# 3.0 solution, and now you want to build, test and package it with a shared build setup between your CI environment (which, of course, doesn’t have Visual Studio installed) and your developer’s machines.
Hopefully this will walk you through most of the potential pitfalls you might find along the way.
This post has been written using an actual build.fsx script that we use for a utility project at 15below. We’re hiring, so if you’re interested in this kind of thing, drop me a line.
Set up
There is no installer for the F# 3 compiler, so we’re going to be playing some games to support building on a TeamCity build agent without VS 2012 installed.
The script assumes a few things about your repository:
a tools directory with the same NuGet and FSharp directories as at https://github.com/fsharp/FAKE/tree/develop/tools (basically a recent nuget.exe in one, and a recent build of the open source F# compiler project in the other)
From here on down is just a heavily commented build.fsx file. I was going to use FSharp.Formatting to nicely format this, but unfortunately the combination of FSharp.Formatting itself and Posterous have defeated me. Something to play with more at a later date.
Hopefully this example will give you a start on using FAKE in real projects.
In future posts I’d like to address some of the more esoteric bits and pieces we’ve been using FAKE for, such as building Octopus deployment packages, running integration tests (with full setup and database deployment) and running unit tests in parallel. Stay tuned…